

Confidential AI
GPU TEE Benchmark
Performance benchmarks and metrics for LLM inference in GPU TEE environments.
Benchmark Overview
As confidential AI gains traction for privacy-preserving applications, evaluating the performance overhead of running LLM in TEE on GPUs is essential. This benchmark provides developers with quantitative insights into GPU TEE efficiency.GPU TEE Performance
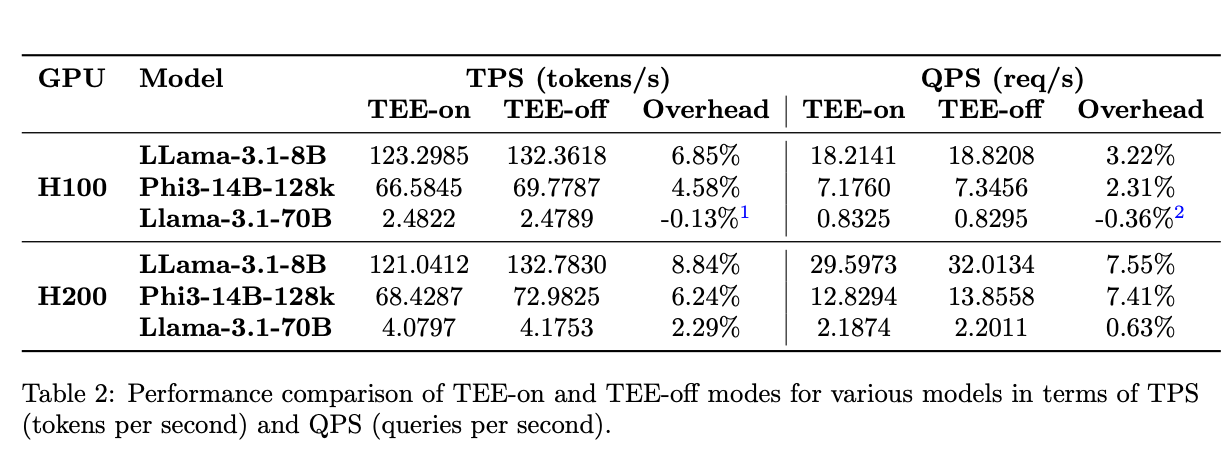
Benchmark