Confidential AI
Host LLM in GPU TEE
Run Large Language Models securely in GPU Trusted Execution Environment (TEE) for confidential AI.
Overview
Private AI or called confidential AI addresses critical concerns such as data privacy, secure execution, and computation verifiability, making it indispensable for sensitive applications. As illustrated in the diagram below, people currently cannot fully trust the responses returned by LLMs from services like OpenAI or Meta, due to the lack of cryptographic verification. By running the LLM inside a TEE, we can add verification primitives alongside the returned response, known as a Remote Attestation (RA) Report. This allows users to verify the AI generation results locally without relying on any third parties.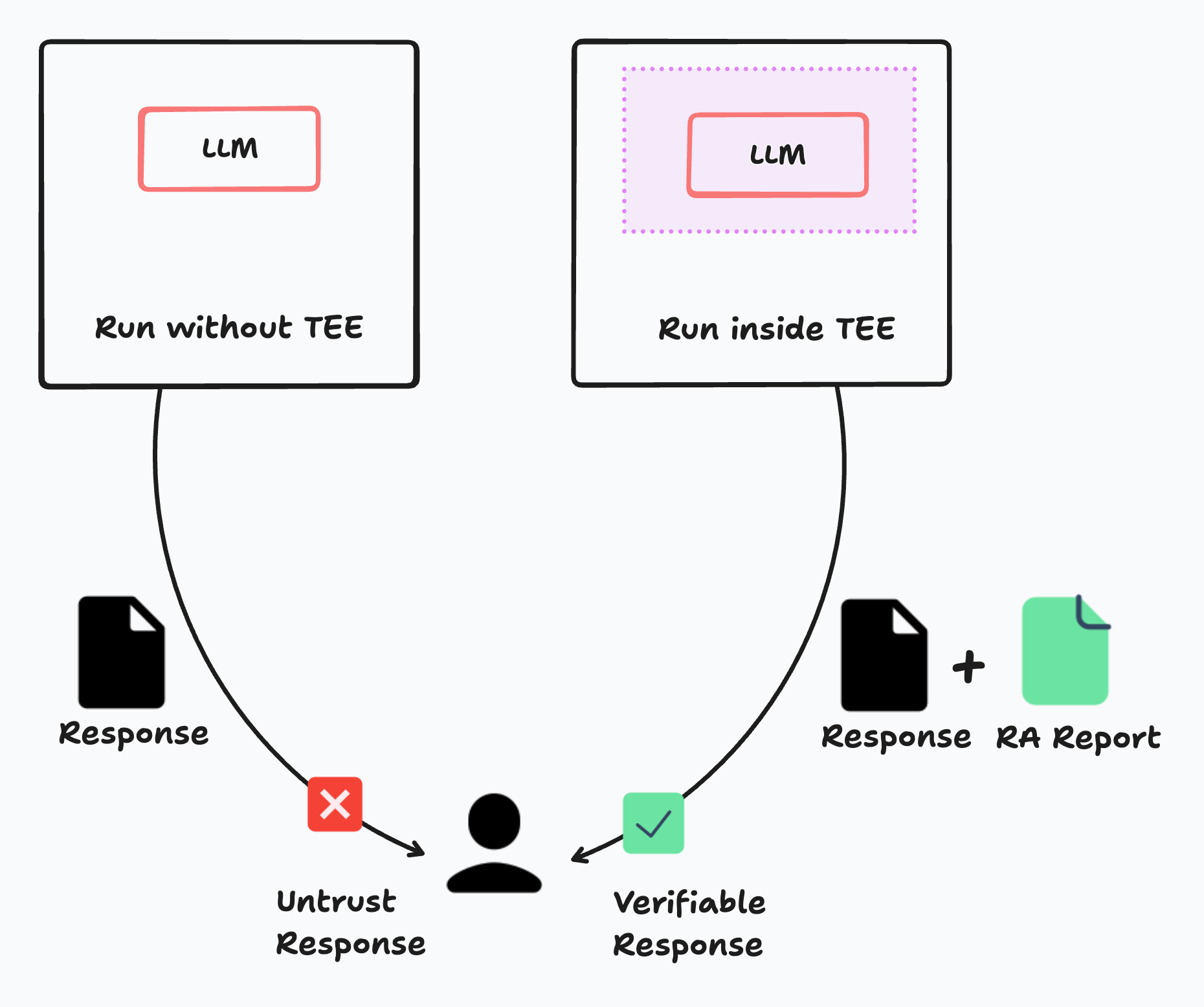
Implementation
The implementation for running LLMs in GPU TEE is available in the private-ml-sdk GitHub repository. This project is built by Phala Network and was made possible through a grant from NEARAI. The SDK provides the necessary tools and infrastructure to deploy and run LLMs securely within GPU TEE.